Safe Autonomy
Autonomous systems are being increasingly deployed in environments, where safety is of fundamental importance. Accidents involving self-driving vehicles, for instance, demonstrate the need for safe operation in autonomous systems. These systems are required to make decisions under uncertainty while attaining safety.
From a modeling perspective, the partially observable Markov decision process (POMDP) framework is general enough to model a variety of real-world sequential decision processes and can be used to analyze and design many learning-based autonomous systems. A POMDP is a generalization of a Markov decision process (MDP). A POMDP models an agent’s decision process, in which it is assumed that the system dynamics are determined by an MDP, but the agent cannot directly observe the underlying state. Instead, it must maintain a probability distribution (belief) over the set of possible states, based on a set of observations and observation probabilities, and the underlying MDP.
Nonetheless, POMDPs are often computationally intractable to solve exactly, so computer scientists have developed methods that approximate solutions for POMDPs. Several promising point-based methods via finite abstraction of the belief space are proposed in the literature. Yet, these techniques often do not provide any guarantee for safety or optimality. That is, it is not clear whether the probability of satisfying the safety/optimality requirement is an upper-bound or a lower-bound for a given POMDP. Establishing guaranteed performance is of fundamental importance in safety-critical applications, e.g. aircraft collision avoidance, and Mars rovers.
I borrow notions from control theory to address some of these challenges in studying POMDP representations of AI and machine learning systems, without the need for finite abstraction.
I borrow notions from control theory to address some of these challenges in studying POMDP representations of AI and machine learning systems, without the need for finite abstraction.
Treating POMDPs as Hybrid Systems
As mentioned above, since the states are not directly accessible in a POMDP, decision making requires the history of observations. Therefore, we need to define the notion of a belief or the posterior as sufficient statistics for the history. Given a POMDP with finite states , finite actions , and finite observations , the belief denotes the probability of the system being in state at time . The evolution of the beliefs over time can then be derived in closed-form using Bayesian inference as
where is the given observation probabilities (sensor model), is the given transition probabilities, and the beliefs belong to the belief unit simplex
A policy in a POMDP setting is then a mapping , i.e., a mapping from the continuous beliefs space into the discrete and finite action space.
I represent the belief update equation as a discrete-time switched system, where the actions define the switching modes. Formally, the belief dynamics can be described as
where are the observations representing inputs, and denote the discrete time instances. This switched system representation allows me to use tools from hybrid systems literature to analyze POMDPs.
I represent the belief update equation as a discrete-time switched system, allowing me to use tools from hybrid systems literature to analyze POMDPs.
To illustrate, the figure below shows the belief evolution of a POMDP modeled by a state-dependent switched system induced by the policy .

Based on this switched system representation, I verified the safety and/or optimality requirements of a given POMDP by formulating a barrier certificates theorem. I showed that if there exist a barrier certificate satisfying a set of inequalities along the belief update equation of the POMDP, the safety/optimality property is guaranteed to hold. These conditions can be computationally implemented as a set of sum-of-squares programs.
The figure below illustrates this framework: Instead of solving the POMDP, I find a barrier certificate whose zero-level sets separate the evolutions of the belief update equation from a set of initial beliefs , and a pre-specified set that characterizes safety or optimality. If such a barrier certificate exists, then .

In fact, many problems in autonomy can be described as verifying (or synthesizing a policy such that) . In the following, I will briefly outline few of them.
In fact, many problems in autonomy can be described as verifying (or synthesizing a policy such that) . In the following, I will briefly outline few of them.
Application: Machine Teaching with Guarantees
The demand for machine learning models has skyrocketed in the past few years, as more and more sectors in industry and services rely on them. This has led to a shortage of machine teachers that can build those models. One solution to the increasing demand is to make teaching machines easy, fast, and universally accessible.
Machine teaching is a paradigm shift from machine learning in that machine teaching is focused on passing on the knowledge rather than discovering knowledge (as is the case in the machine learning methods). Given a learning algorithm and a target model, a machine teaching algorithm finds an optimal (often the smallest) training set. For an illustration, see the example in the figure below.
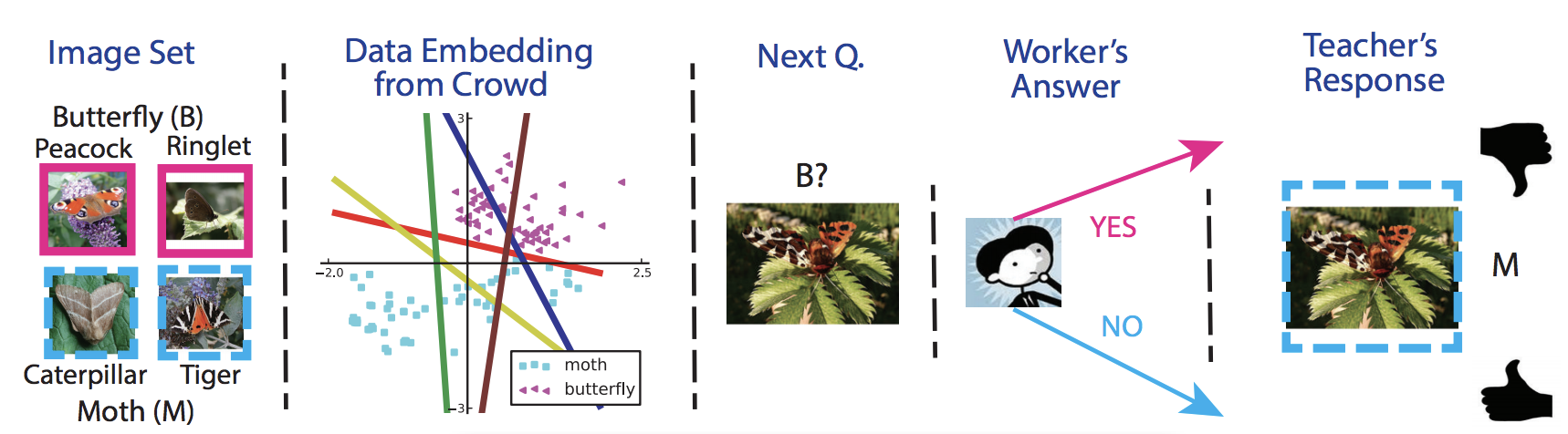
A fundamental setback to many promising machine teaching techniques in the literature is that their performance is not guaranteed. In control theory, however, an algorithm is guaranteed to work, because there exists a certificate, e.g. a Lyapunov function. To propose guaranteed machine teaching methods, I formulated a POMDP representation for machine teaching techniques and used barrier certificates to guarantee teaching performance.
To propose guaranteed machine teaching methods, I formulated a POMDP representation for machine teaching techniques and used barrier certificates to guarantee teaching performance.
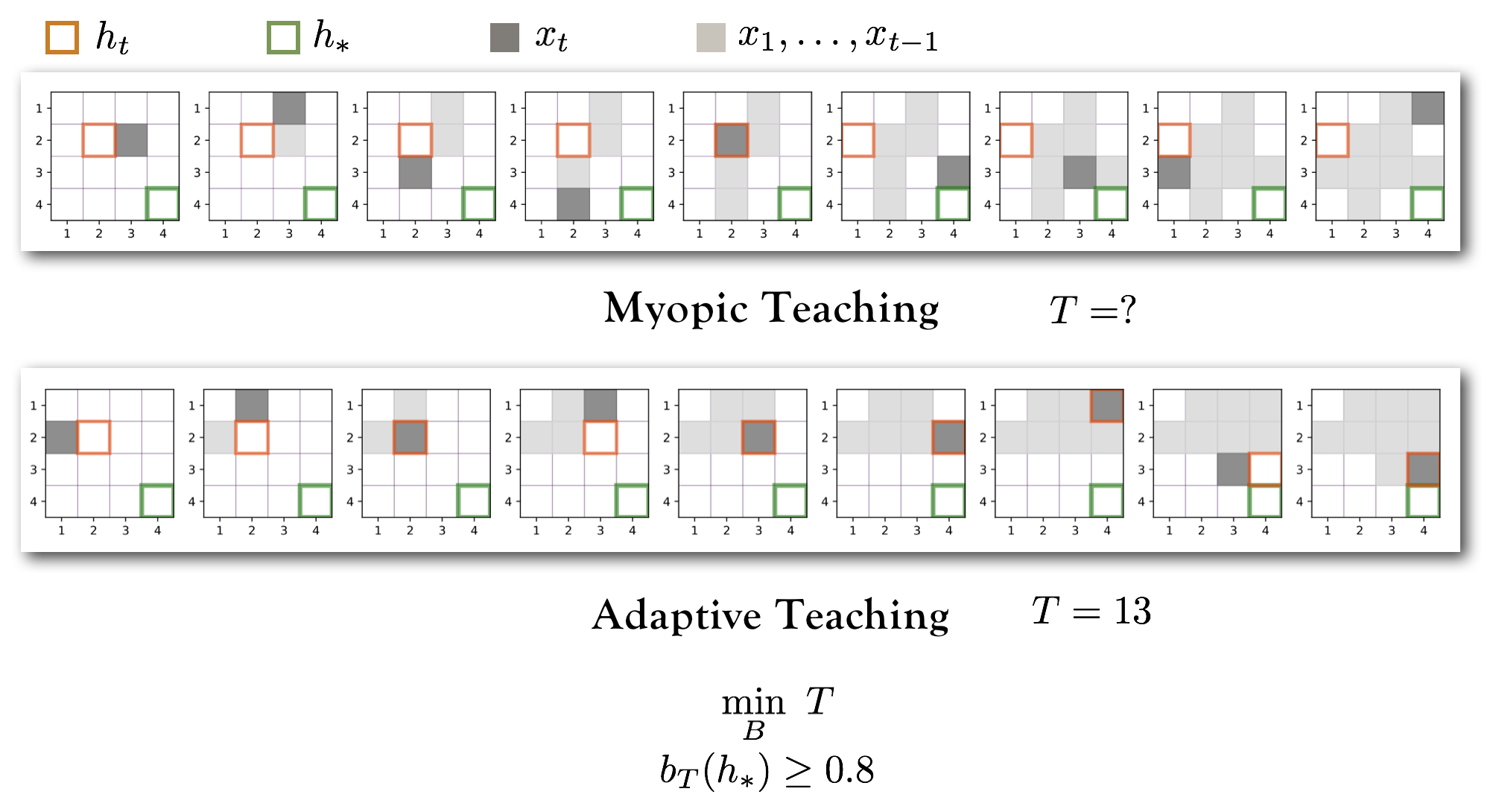
The figure below illustrates the use of barrier certificates to compare two machine teaching algorithms (see Chen et. al. for more details on the algorithms). Based on a barrier certificates of degree 2, I was able to certify that the adaptive teaching method is guaranteed to teach (the location of the target) with probability greater than 0.8 in 13 steps; whereas, no certificate for the myopic teaching method could be constructed. Numerical experiments validate this result.
Application: Safe Imitation Learning
Imitation learning methods are concerned with mimicking human behavior in a given task. An agent (a learning machine) is trained to perform a task from demonstrations by learning a mapping between observations and actions.
In imitation learning, we need to iteratively roll out a trained model to collect trajectories and update the model based on some feedback collected on those trajectories. In safe-critical applications, one would want to impose safety constraint for roll-outs during training.
Imitation learning algorithms can also be modeled as POMDPs. Therefore, we can use barrier certificates to guarantee safety of imitation learning methods.
Imitation learning algorithms can also be modeled as POMDPs. Therefore, we can use barrier certificates to guarantee safety of imitation learning methods.
As an illustration, consider a human giving demonstrations to a robotic arm to close a microwave door. As the articulation relationships of the objects do not remain static in time (such as for a microwave), while in the active learning phase, a robot can take some actions that result in a change in the articulation relationship of object. This can cause in belief divergence over the object model. To avoid this, one straightforward approach is to use hard constraints which define the geometric boundaries of these models. We can find a barrier certificate that ensures no transition in articulation state of the object occurs for a given initial state and a set of actions (see the video below).
Application: Privacy in Cyber-Physical Systems
Privacy is becoming a rising concern in many modern engineering systems, which are increasingly connected over shared infrastructures, such as power grids, healthcare systems, smart homes, transportation systems, and etc. Potentially malicious intruders may have access to the information available publicly or privately based on which they attempt to infer some “secret” associated with the system, such as personal activity preferences, health conditions, and bank account details. If the privacy is compromised, it could lead to substantial social or economic loss. Therefore, it is of fundamental importance to design cyber-physical systems that are provably safe against privacy breaches.

In recent years, a privacy notion called opacity has received significant attention. Generally speaking, opacity is a confidentiality property that characterizes a system’s capability to conceal its “secret” information from being inferred by outside observers. These observers are assumed to have full knowledge of the system model, often as a finite automaton, and can observe or partially observe the behaviors of the system, such as the actions performed, but not the states of the system directly. Therefore, POMDPs are a natural framework to model such scenarios.
Hence, the notion of opacity I use is defined on the belief space of the intruder. That is, the privacy requirement requires that the intruder is never confident that the system is in the secret state with a probability larger than or equal to a constant , at any time :
In order to verify given a POMDP whether a privacy requirement is satisfied or not it suffices to define . Obviously, if no solution of the system is in . Then, we have .
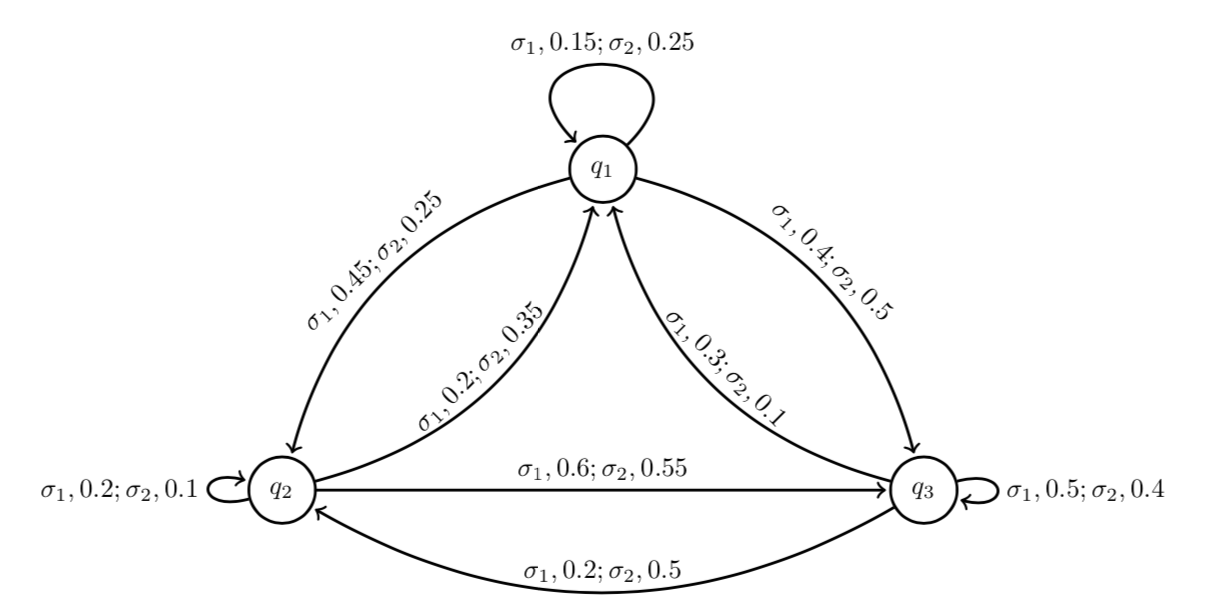
The figure below shows the POMDP model for an inventory management system, with two actions and three states representing different inventory levels of a company. The states correspond to the low and high inventory levels, respectively, and are the secret states. If the intruder, say a competitor or a supplier, has information over the current inventory levels being high or low, they may manipulate the price of the goods, and thus negatively affect the company’s profit. Therefore, it is of the company’s interest to conceal the inventory levels from the potential intruders. That is, the company seeks to maximize such that .
In the table below, I report the results on the upper-bound of obtained by increasing the degree of the barrier certificates.
| 2 | 4 | 6 | 8 | 10 | |
|---|---|---|---|---|---|
| 0.93 | 0.88 | 0.80 | 0.74 | 0.69 |
Application: Multi-Robot Safe planning
I introduced a safety shield concept that uses the proposed discrete-time barrier functions for POMDPs to ensure the satisfaction of a set of high-level mission specifications in terms of temporal logic formulae. This was carried out by formulating logical compositions of barrier functions and results for finite-time reachability. Given a nominal policy, e.g. by a an expert or some control algorithm, the safety shield, which is implemented online, assures the satisfaction of high-level specifications with minimal interference. We demonstrated the efficacy of the proposed method with a team of heterogeneous robots including a Segway, a quadrotor, and a flipper robot trying to locate an object while avoiding several obstacles in CAST.



Application: Robust Decision Making
Most formulations assume the the transition and the observation probabilities for POMDPs are explicitly given. However, unforeseeable events, such as (unpredictable) structural damage to a system or an imprecise sensor model, necessitate a more robust formalism. This problem is directly related current challenges for the area of artificial intelligence, referred to as robust decision-making and safe exploration. Concretely, the problem is to provide a policy for an (autonomous) agent that ensures certain desired behavior by robustly accounting for any uncertainty and partial observability that may occur in the system. The policy should be optimal with respect to some performance measure and additionally ensure safe navigation through the environment.
Formally, I consider POMDPs with interval uncertain transition and/or observation probabilities and where denote the set of triplets corresponding to the uncertain transition probabilities (similar definition for ).
Then, based on the hybrid system model, the robust decision making problem can be cast as a safety verification problem of an uncertain hybrid system.
Based on the hybrid system model, the robust decision making problem can be cast as a safety verification problem of an uncertain hybrid system.
I demonstrated the applicability of my methods using barrier certificates on a variant of the RockSample problem defined on a grid with 2 rocks.

In this problem, a Mars rover explores a terrain, where “scientifically valuable” rocks may be hidden. The locations of the rocks are known, but it is unknown whether they have the type “good” or “bad”. Once the rover moves to the immediate location of a rock, it can sample its type. As sampling is expensive, the rover is equipped with a noisy long-range sensor that returns an estimate on the type of the rock. The accuracy of the sensor decreases with the distance to the rock (thus, we have uncertain observation probabilities). Also, the states on the bottom of the grid are slippery sand dunes and should be avoided.
Based on barrier certificates, we find two policies such that the Mars rover can discover the rock types by maximizing
and also reaching the goal region safely. The figure shows how these two policies evolve.
