Perception-Aware Autonomy
Emerging applications in autonomy require autonomous agents that can actively perceive or sense the uncertain environment and make decisions. Furthermore, the decision making method need to take into account communication constraints, while satisfying high-level mission specifications
For instance, in the upcoming Mars 2020 rover mission, a Mars rover is tasked to safely explore an uncertain environment and coordinate with a scouting helicopter. Since the energy supply of Mars rovers is limited (produced from a thermoelectric generator), the communication between the Mars rover and helicopter can result in further power consumption and reduce the lifetime of the rover. Missions of such sophisticated nature will necessitate on-board autonomy. Nonetheless, tight sensing constraints, due to the power consumption of on-board sensors and transmitters, and bandwidth limitation on data sent from the Earth and orbiting satellites further complicates the navigation task. In these cases, it is necessary for autonomous agents to make decisions to complete an specified task with optimal information cost involved for perception.

Markov Decision Processes with Perception Costs
Markov decision processes (MDPs) are one of the most widely studied models for decision-making under uncertainty in the fields of artificial intelligence, robotics, and optimal control.
I model the interaction between an autonomous agent and an uncertain environment using an MDP. In order to account for the perception costs, I consider an additional cost term in terms of transfer entropy. We use the additional transfer entropy cost to quantify the directional information flow from the state of an MDP (representing the uncertain environment or the location of the autonomous agent) to the control policy. By minimizing the transfer entropy, I promote randomized policies that rely less on the knowledge of the current state of the system. I also consider high-level mission specifications that are defined in terms of linear temporal logic (LTL) formulae.
Let and be a finite set of states and actions, respectively, for an MDP and , with upper case letters denoting random variables and lower case ones their instantiations. The transfer entropy is given by
where the conditional mutual information is described as
wherein, denotes the policy and is the joint states and actions distribution. Then, formally, I consider the following sequential decision making problem
that is, maximizing the probability of satisfying the specification given by formula given the sensing budget . Alternatively, I optimize the weighted sum of both the probability of satisfying the specifications and the transfer entropy term.
The figure below shows an example of sensing-aware autonomous navigation satisfying the LTL formula ‘crash’ ‘goal’ (do not hit the obstacles until you reach goal region).



Stochastic Games with Perception Costs
Stochastic games, introduced by Shapely in 1953, are dynamic games over a sequence of stages with probabilistic transitions. At the beginning of each stage the game is in some state. The players select actions and each player receives a payoff that depends on the current state and the chosen actions. The game then moves to a new random state, whose distribution depends on the previous state and the actions chosen by the players. Stochastic games can be used to model and analyze discrete systems operating in an unknown (adversarial) environment. Applications of such games run the gamut of computer networks to economics.
However, in real-world games involving autonomous agents making decisions under uncertainty, the agents have a limited perception or information budget, since information acquisition, processing, and transmission are costly operations. In particular, in two-player uncertain adversarial environments, where one player enters the opponent’s territory, we seek a wining strategy with minimum sensing.
I considered finite two-player stochastic games, wherein in addition to the conventional cost over states and actions of each player, I included the perception budget in terms of transfer entropy. Formally, my goal was to find strategies and that solve the following class of dynamic stochastic games
where is the total payoff function, is the transfer entropy for the (good) player, is the transfer entropy for the adversary, and . In particular, I am interested in the case , since I often assume the adversary has full access over its states.
I found a set of pure and mixed strategies for such a game via dynamic programming. The application of dynamic programming leads to a set of coupled nonlinear equations that I solve using the modified Arimoto-Blahut algorithm.
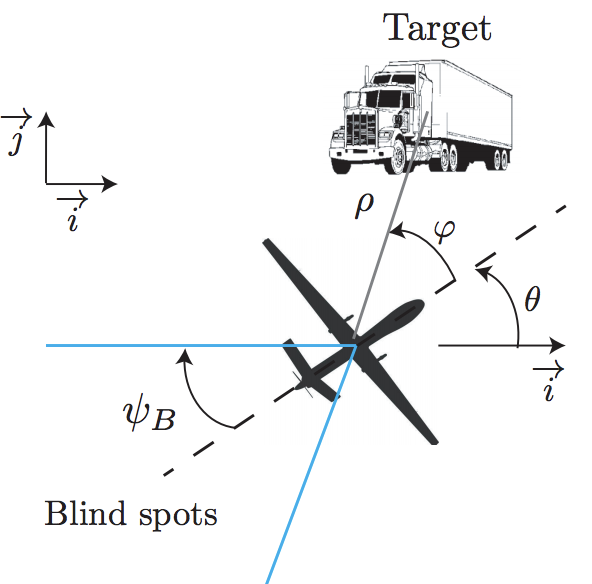
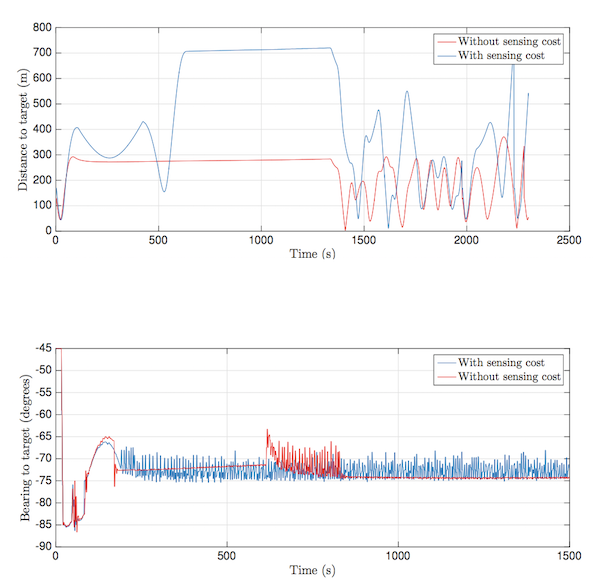
I considered a case study of a UAV vision-based target tracking task of an (evasive) ground vehicle using UAV simulation environment OpenAMASE developed at Air Force Research Laboratory. The goal of the UAV is to keep the adversarial ground vehicle in the field of view of its camera despite the evasive maneuvers of the ground vehicle.